Student Achievement Classification
Machine Learning Project: Student Achievement Classification
Introduction
This project applies machine learning algorithms to classify student performance. Traditional methods of categorizing student performance are inefficient and inaccurate. This project utilizes machine learning to optimize this process, providing a more effective solution.
Abstract
The project focuses on feature engineering to optimize dataset features, particularly for student achievement and classification datasets. It implements binary classification to solve open set problems and uses supervised learning algorithms to enhance accuracy.
Highlights
- Feature Engineering: Optimize dataset features to improve machine learning algorithm effectiveness.
- Binary Classification: Solve open set problems effectively.
- Supervised Learning Algorithms: Achieve high accuracy in model evaluation.
- Unsupervised Models: Optimize clustering results based on contour coefficients.
Project Overview
- Objective: Improve the classification of student performance using machine learning.
- Methodology: Utilizing feature engineering, supervised and unsupervised learning algorithms to optimize classification accuracy.
- Technologies Used: Python, scikit-learn, pandas, NumPy, matplotlib.
Algorithms Used
- Matrix Decomposition: By decomposing a large matrix into two smaller matrices, we can reduce dimensionality and compress a large amount of data. This is crucial for handling and analyzing complex datasets efficiently.
Example Formula:
P[i][k] = P[i][k] + alpha * (2 * eij * Q[k][j] - beta * P[i][k]) Q[k][j] = Q[k][j] + alpha * (2 * eij * P[i][k] - beta * Q[k][j]) - K-Proximity Algorithm: Utilized for categorizing data based on the similarity of samples in the feature space, using Euclidean distance for calculations.
Open Set Problem
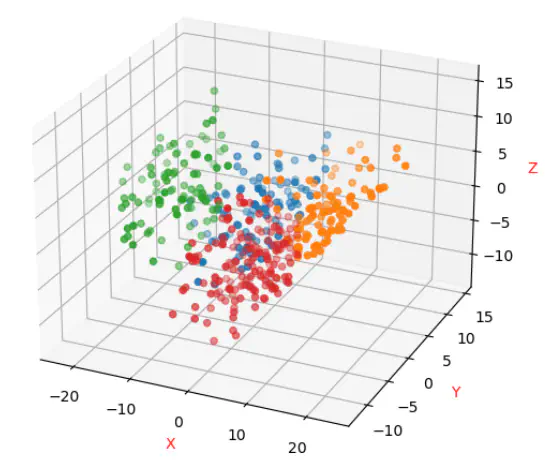
Before training the model, it’s crucial to address the open set problem associated with this dataset. This dataset presents an open-set classification challenge due to the existence of category “0”. This category not only includes normal categories ranging from 1 to 4 but also encompasses other unknown categories, such as 0. However, these unknown categories lack specific labels, preventing the classifier from recognizing the exact categories of these unknowns based on the existing data. Hence, they collectively form one category: “0”. The set S contains N finite categories with specific labels, and S includes K finite or infinite unknown categories. The open set classification challenge is to segregate these N categories and reject these K unknown categories.
To tackle this issue, the Support Vector Machine (SVM) was chosen for its ability to define half-spaces and classify data of any type. This approach results in dividing the half-plane so that the training samples are on one side and the non-training samples on the other. Initially, the data labels were modified to group categories 1-4 into one class and category 0 into a separate class. This modified data was then fed into the SVM for training. During the training phase, the C value was set to 2, the kernel function was ‘rbf’ (Linear kernels), the gamma parameter was 10, and a one-to-many strategy was employed for training. Further solutions to the open set problem would require algorithmic optimization to address both empirical risk and open set risk, which are not considered in this experiment. The open set identification challenge is defined as minimizing both empirical and open set risks, with this experiment focusing on the SVM method to optimize its open set risk with an F-score as the objective.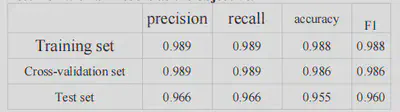
Project Goals
- To improve the accuracy and efficiency of student performance classification.
- To implement and compare different machine learning techniques for better results.
- To develop a scalable and adaptable machine learning model for educational data.
Repository
The project’s code and additional resources are available on GitHub: Songming Ping’s GitHub
Conclusion
This project demonstrates the potential of machine learning in educational data analysis and classification, showcasing significant improvements over traditional methods in both accuracy and efficiency.
Songming Ping
Imperial College London | MRes Medical Robotics and Image-Guided Intervention
My research interests include human-computer interactive devices, reinforcement learning algorithms, deep learning algorithms, interactive technologies, digital twins, and automated systems.